Ref : https://wikidocs.net/22644
09. 워드 임베딩(Word Embedding)
텍스트를 컴퓨터가 이해하고, 효율적으로 처리하게 하기 위해서는 컴퓨터가 이해할 수 있도록 텍스트를 적절히 숫자로 변환해야 합니다. 단어를 표현하는 방법에 따라서 자연어 처리의 성…
wikidocs.net
https://blog.kakaocloud.com/163
<지식 사전> 임베딩(Embedding)이란? LLM에서의 역할과 응용
안녕하세요, 카카오클라우드입니다. 최근 LLM의 발전과 함께 임베딩(Embedding)이라는 용어를 자주 접하게 됩니다. 임베딩은 텍스트, 이미지 등의 데이터를 벡터 공간에 표현하는 기술로 LLM의 성능
blog.kakaocloud.com
<Embedding이란?>
텍스트 데이터, 이미지 데이터, 음성 데이터.. 등 어떤 데이터든, 컴퓨터가 이해할 수 있는 데이터의 형태로 바꾸어야 한다.
Embedding은 데이터를 컴퓨터가 이해할 수 있는 숫자 벡터로 변환하여, 고차원의 데이터에 대해 주요한 특징을 요약해서, 저차원의 벡터 공간에 담아낸다. 복잡한 데이터를 더 간결하고 효율적으로 표현할 수 있다.(벡터의 차원 수는 벡터의 크기(길이)를 의미한다)
데이터를 Embedding으로 만들면, 이를테면 아래와 같은 작업을 수행할 수 있다.
▶ 벡터간의 코사인 유사도, 유클리드 거리 등을 계산하여 데이터간의 관계 파악 (e.g. 문장간 유사도 측정, 클러스터링 등)
▶ Classification, Regression 등 (Embedding을 입력으로 받아 특정 클래스로 분류하거나, 회귀를 통해 값을 예측하거나 ..)
▶ Feature Extraction : Embedding Vector가 데이터의 주요 특징을 내포하므로, 이를 통해 새로운 분석을 해낼 수도 있다 (e.g. "아메리카노" - "따뜻함" + "차가움" = "아이스 아메리카노")
Embedding을 이용하면 텍스트 데이터, 이미지 데이터, 음성 데이터 등 다양한 데이터 타입을 공통된 Vector Space에서 표현할 수도 있다.
<벡터 유형>
Embedding을 통해 만들어진 벡터도 굳이 구분하자면, Sparse한 벡터(Sparse Representation), Dense한 벡터(Dense Representation)로 구분할 수 있다.
[Sparse Representation] - Sparse한 벡터로 Embedding 나타내기
One-Hot 벡터처럼, 벡터(또는 행렬)값을 대부분 0으로 채워서 표현하는 방식을 Sparse Representaion이라고 한다.
Word Embedding을 예로 들면, Sparse하게 임베딩할 경우, 벡터의 차원 하나 당 단어 하나가 되는 셈이다.
e.g.
강아지 = [0, 0, 1, 0 ... 0] (벡터 사이즈가 Vocab Size와 동일해질 수 있다(매우 커질 수 있다))
고양이 = [0, 0, 0, 1 ... 0]
이렇게되면 벡터의 차원이 엄청 커지고, 대부분의 의미없는 공간이다. → 공간적인 낭비
[Dense Representation] - Dense한 벡터로 Embedding 나타내기
Dense하게 표현하는 방식은 Sparse방식처럼 단어와 벡터 차원을 일대일 대응시키지 않는다.
어떤 단어든, 사용자가 정의한 차원수에 맞춰서 단어를 표현한다.
e.g.
강아지 = [0.2 ,1.8, 1.1, -2.1, 1.1, 2.8 ... ] (벡터 사이즈 : 사용자가 정의한 차원(예를 들어 128))
벡터의 차원이 조밀해졌다고 하여 Dense Vector라고 한다.
<텍스트 Embedding>
텍스트 데이터에 대한 Embedding을 살펴보면, 아래와 같다.
[Word Embedding] - 단어를 기반으로 Embedding 형성 (Word2Vec, GloVe, FastText 등)
Word2Vec, GloVe, FastText 모두 임베딩 벡터를 Dense하게 표현한다(Distributed Representation, 분산 표현 이라고도 함).
Distributed Representation은 분포 가설(Distributed Hypothesis, 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다는 가정)이라는 가설 하에 만들어지는 표현 방법이다.
- Word2Vec
Word2Vec의 학습 방식에는 CBOW(Continuous Bag of Words), Skip-Gram 두 가지 방식이 있다.
간단한 예시로, 아래 문장을 생각해보자.
"The fat cat sat on the mat" → ['The', 'fat', 'cat', 'sat', 'on', 'the', 'mat']
1. CBOW
CBOW는 주변 단어를 입력으로, 중심 단어를 예측하는 방식이다.
Embedding을 형성하고자 하는 목표 단어에 대한 Embedding을 형성할 때, 주변에 어떤 단어들이 위치했었는지 학습해둔 것을 기반으로, 목표 단어를 Embedding한 후에 벡터 공간의 어디에 놓일지를 결정하는 식이다(주변에 있는 단어와 가깝게).
['The', 'fat', 'cat', 'on', 'the', 'mat'] 으로부터 'sat'을 예측하는 간단한 예시를 생각해보자.
'sat'을 중심 단어, 'sat'을 예측하기 위해 사용하는 단어를 주변 단어라고 한다.
1st. 중심 단어를 예측하기 위해 앞뒤로 몇 개까지의 단어를 볼지 Window Size를 결정한다.
2nd. Window Size를 정하고, Sliding시켜가며 학습을 위한 데이터셋을 만들어간다. Window Size가 2라면 아래와 같은 식이다.

Word2Vec에서 입력은 모두 One-Hot 벡터가 되어야 한다.
위 데이터셋은 중심 단어와 주변 단어를 어떤식으로 선택했는지에 따라, 각각 어떤 One-Hot 벡터가 되는지를 나타내는, 전체 데이터셋이다.
3rd. 중심단어 'sat' 예측

CBOW의 Neural Net을 간단히 도식화한 것이다.
Input Layer의 입력에 Window Size만큼 정의한 주변 단어들이 One-Hot 벡터로 들어가고, Output Layer에서 예측하고자 하는 중간 단어의 One-Hot 벡터를 레이블로서 뽑아내야 한다.
이를 위해 CBOW의 Neural Net을 좀 더 확대해서, 동작 메커니즘을 구체적으로 나타내보자.

Projection Layer의 크기가 5로 나와있으므로, Input Layer의 입력을 Embedding하고나서 차원은 5차원이 된다.
또한, 가중치 W, W' 을 보면, W 의 사이즈 = V*M, W'의 사이즈 = M*V 이다. 이건 두 행렬을 Transpose한 것이 아니라, 서로 다른 행렬이다. (초기 가중치값은 어떤 랜덤한 값으로 초기화되어있다고 생각하자)
CBOW는 주변 단어로 중심 단어를 더 정확히 맞추기 위해 W와 W'을 계속해서 학습해 나가는 구조이다.
4th. 학습이 이루어지는 과정
그럼 CBOW에서 학습이 이루어지는 과정은 어떤식으로 이루어질까? Window Size를 2로한 예시를 다시 보자.

주변 단어(입력값)의 One-Hot 벡터 x는, 그저 i번째 인덱스에서만 1이라는 값을 가진다.
이 벡터와 가중치 W의 행렬 곱은, 사실 W행렬의 i번째 행렬을 "그대로 읽어오는것(Look Up)"과 동일하므로, 이 작업을 Look Up Table이라고 한다.
초기에 랜덤하게 초기화되어있던 W와 W'는, 학습을 하면서 업데이트되며, 이 때 W의 각 행벡터는 점점 각 단어의 Embedding Vector로 간주된다.
어쨌든 다시 돌아와서, 이렇게 되면 주변 단어의 One-Hot 벡터에 대해 가중치 W가 곱해져 생겨난 결과 벡터들은 Projection Layer에서 만나, 이 벡터들의 평균인 벡터를 위 그림의 수식과 같이 구한다.
분모는 주변 단어의 수가 되고(중간 단어가 문장의 끝단에 위치하는 단어가 아니라면), 분자는 각 주변 단어의 Embedding Vector의 합이 된다. 이를 평균낸 값이 중심 단어의 Embedding Vector를 학습하는데 사용된다.
(참고로, Skip-Gram의 경우, 입력값이 중심 단어 하나이므로, Projection Layer에서 투사층에서 벡터의 평균을 구하지 않는다)

위 수식에서 얻은 평균값 벡터를 두 번째 가중치 행렬인 W'와 곱해서, 입력 벡터와 동일한 사이즈의 출력 벡터를 만들어낸다.
이 벡터를 Activation Function(Softmax)에 통과시켜, 벡터의 각 원소값들을 0~1사이의 실수에 Mapping시키고, 총 합은 1이 된다.
다중 클래스 분류 문제를 위한 일종의 Score Vector(yhat)가 된다.
Score Vector의 j번째 인덱스가 가진 값은, "j번째 인덱스에 해당하는 단어가 중심 단어일 확률" 을 의미한다.
y와 yhat 두 벡터 사이의 오차를 줄이기 위해, Loss Function으로 Cross Entropy를 사용한다. 수식으로 나타내면 아래와 같다.

Back Propagation을 수행하면 W, W'가 학습되는데, 학습이 다 되면 5차원(M차원)의 크기를 갖는 W 행렬의 행을 각 단어의 임베딩 벡터로 사용하거나, W와 W'행렬 두 가지 모두를 가지고 Embedding Vector를 사용하기도 한다.
2. Skip-Gram
Skip-Gram은 중심에 있는 단어를 입력으로 주변 단어들을 예측하는 방식이다. 매커니즘 자체는 거의 동일하므로, 간단히만 살펴보자.
위 CBOW의 예시 그대로, Window Size를 2로 한 예시를 보면, 데이터 셋은 아래와 같이 구성될 것이다.

신경망은 도식화하면 아래와 같은 식일 것이다.

앞서 언급했든, 중심 단어로 주변 단어를 예측하는 형태이므로, CBOW처럼 평균값을 구하는 수식은 없다.
여러 논문에서 성능을 비교했을때 CBOW > Skip-Gram 이라고는 하던데, Task등에 따라 적절히 잘 판단하는것이 맞다고 생각한다.
cf.
Word2Vec 실습은 아래를 참조하자.
09-03 영어/한국어 Word2Vec 실습
gensim 패키지에서 제공하는 이미 구현된 Word2Vec을 사용하여 영어와 한국어 데이터를 학습합니다. ## 1. 영어 Word2Vec 만들기 파이썬의 gensim 패키지…
wikidocs.net
09-04 네거티브 샘플링을 이용한 Word2Vec 구현(Skip-Gram with Negative Sampling, SGNS)
네거티브 샘플링(Negative Sampling)을 사용하는 Word2Vec을 직접 케라스(Keras)를 통해 구현해봅시다. ## 1. 네거티브 샘플링(Negative Samp…
wikidocs.net
- GloVe (Global Vectors for Word Representation)
기존의 Word Embedding기법인 LSA와 Word2Vec을 보완하는 컨셉으로 등장한 것이 GloVe이다.
GloVe는 카운트 기반과 예측 기반을 모두 사용하는 Word Embedding 방법론이다.
cf.
LSA : 카운트 기반으로 Corpus의 전체적인 통계 정보를 고려할 수 있으나, 유추 작업(e.g. 왕:남자 = 여왕:? (정답은 여자))에 약하다. DTM(Document Term Matrix), TF-IDF(Term Frequency-Inverse Document Frequency) 행렬처럼, 각 문서에서 각 단어의 빈도수를 카운트한 행렬(전체적인 통계 정보)를 입력으로 받아, 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내는 기법이다.
Word2Vec : 예측 기반이므로, 유추 작업에는 강하지만 Embedding Vector가 Window 크기 내에서만 주변 단어를 고려하므로, Corpus의 전체적인 통계 정보를 반영하지 못한다. 실제값과 예측값에 대한 오차를 손실함수를 통해 줄여가며 학습하는 예측 기반의 방법론이다.
GloVe가 Word2Vec만큼 뛰어난 성능을 보인다고 알려져있다고 하는데, 이건 Task에 따라 둘 다 써보고 판단하도록 하자.
GloVe에서는 (윈도우 기반)동시 등장 행렬(Window based Co-occurence Matrix), 동시 등장 확률(Co-occurence Probability) 이라는 두 가지 개념이 등장한다.
1. (윈도우 기반)동시 등장 행렬(Window based Co-occurence Matrix)
단어의 동시 등장 행렬은, 단어 간의 동시 등장 빈도를 나타낸 행렬로, 특정 단어가 다른 단어와 같은 문맥에서 몇 번 등장했는지 측정한다.
즉, 행과 열을 전체 단어 집합의 단어들로 구성하고, Window Size 내에서 단어 i와 단어 k가 등장한 횟수를 i행 k열에 기재한 행렬이다.
예를 들어, 아래와 같이 3개의 문서로 구성된 텍스트 데이터가 있다고 하자.
"I like deep learning"
"I like NLP"
"I enjoy flying"
텍스트 데이터가 위와 같다면, Vocab은 아래와 같을 것이다.
["i", "like", "enjoy", "deep", "learning", "NLP", "flying"]
Window Size가 N이라면, 좌우로 존재하는 N개의 단어만 참고한다. Window Size를 1이라고 가정하고, 위 텍스트를 기반으로 구성한 동시 등장 행렬은 아래와 같다.

(아래로 내려가면서, 해당 단어 좌우로 1칸(Window Size)씩 봤을 때, 그 열의 단어가 Window에 포함될 경우 +1 한다.)
어쨌든 중요한 점은, 단어간의 동시 등장 빈도를 동시 등장 행렬에 나타내서, 전체 Corpus 내에서 각 단어가 서로 얼마나 자주 함께 등장하는지를 카운트하여, 이를 기반으로 단어 간의 연관성을 판단할 수 있게 된다. (단어 간의 전역적인 관계(전체 통계 정보)를 학습하게 된다.)
참고로, 동시 등장 행렬은 전치시켜도 동일한 행렬이 된다.
2. 동시 등장 확률(Co-occurence Probability)
동시 등장 확률은, 동시 등장 행렬을 기반으로 동일하게 테이블로 나타내볼 수 있다.
동시 등장 확률은 P(k|i) 형태로 나타내며, 단어 i의 전체 등장 횟수를 카운트하고, 단어 i가 등장했을 때 단어 k가 등장한 횟수를 카운트하여 계산하는 조건부확률이다. 즉, 전체 Corpus에서 특정 단어 쌍이 같이 자주 등장한다면, 높은 확률 값을 가진다.
손실 함수는 동시 등장 확률을 잘 예측하도록 Word Embedding을 조정하는 방향으로 학습한다.
- FastText
Word Embedding Vector를 만드는 또 다른 방법으로, FastText가 있다. Word2Vec이 나오고 곧이어 나온 것이라, Word2Vec의 확장판으로 보면 쉽다.
차이점이라면, Word2Vec은 최소 단위가 단어이지만, FastText는 최소 단위가 Subword이다(하나의 단어 안에서도 더 쪼갤 수 있다고 본다)
Subword를 만들 때는, n-gram기반으로 만든다.
e.g.
n=3일 경우, "apple"의 Subword는 아래와 같이 만들 수 있다.
<ap, app, ppl, ple, le>
또한, Subword만 쓰는 것이 아니라, 원본 단어도 사용한다.
<apple>
즉, 총 6개의 토큰을 벡터화한다.
토큰을 벡터화한다는 것은, Word2Vec을 수행하는 것이라고 보면 된다.
원본 단어와 Subword를 Word2Vec으로 벡터화한 것의 총 합이 단어 "apple"의 FastText에서의 Embedding이 된다.
FastText의 장점은, 크게 두 가지 정도를 꼽을 수 있다.
1. 모르는 단어(OOV)에 대응할 수 있다.
FastText의 Neural Net을 학습한 뒤, 데이터셋에 있는 모든 단어의 각 n-gram에 대해 Word Embedding을 형성하는데, 이 때 데이터셋이 충분히 클 경우, Subword를 이용해서 몰랐던 단어(OOV)에 대해서도 대처할 수 있다.
예를 들어, birthplace라는 단어가 OOV라고 해보자. 여기서 birth와 place를 Subword를 통해 알고있었다면, birthplace에 대해서도 벡터를 얻어낼 수 있다. (Word2Vec, GloVe와는 OOV에 대처하는 부분이 확연히 다름)
2. 단어 집합 내에서 빈도수가 적었던 단어에 대해 대응할 수 있다.
Word2Vec의 경우, 등장 빈도가 적은 단어에 대한 Embedding은 정확도가 높지 않았다. 등장하질 않으니, 해당 단어에 대해 볼 기회가 많지 않기 때문에 Embedding또한 정확하게 형성하지 못하는 것이다.
그러나 FastText의 경우, 데이터셋 내의 SubWord를 통해 부분적인 단어를 매우 많이 알고있기때문에, 이를 조합해서 등장 빈도가 적은 단어에 대해서도 정확하게 Embedding을 만들어낼 수 있게된다.
비슷한 이유에서, FastText는 Noise가 많은 Corpus에 대해서도 강점을 갖는다.
대부분의 비정형 데이터는 오타가 섞이거나, 맞춤법이 틀리다거나.. 데이터가 깔끔한 경우가 드문데, 이렇게 Noise가 섞인 단어 또한 등장 빈도가 적은 단어의 일종으로 볼 수 있다.
예를 들어 "appple"을 본다면, 3-gram을 예로 들었을 때, "<ap, app, ppp, ppl, ple, le> + <appple>" 과 같은 형태로 토큰화 후 Embedding이 만들어질텐데, 이러한 Subword 패턴은 "apple"과 거의 유사한 패턴을 공유하므로, "apple"과 비슷한 Vector Space에 위치하게 된다. (즉 Noise에 대해 강건하다)
[Sentence Embedding] - 문장이나 문서를 기반으로 Embedding 형성
Word Embedding은 단어 단위로 Embedding을 만든다면, Sentence Embedding은 문장 전체, 구 등 긴 텍스트에 대한 Embedding을 만들어낸다.
Sentence Embedding은 Word Embedding에 비해 좀 더 고급진(?) 기법으로 볼 수 있는데, 일단 Word Embedding을 바탕으로 더 발전한 Embedding기법이기도 하고, 문맥적인 정보를 더 잘 반영한다거나, 문장 단위의 표현을 해야하므로 더 높은 표현력이 필요하고.. 어쨌든 Word Embedding보다 고급진 기법이라고 보면 될 듯 하다.
Sentence Embedding에는 Sentence-BERT, USE(Universal Sentence Encoder)과 같은 기법이 있다. 이 중 Sentence-BERT만 다뤄보자.
- Sentence-BERT (SBERT)
Ref : https://wikidocs.net/156176
17-07 센텐스버트(Sentence BERT, SBERT)
BERT로부터 문장 임베딩을 얻을 수 있는 센텐스버트(Sentence BERT, SBERT)에 대해서 다룹니다. ## 1. BERT의 문장 임베딩 BERT로부터 문장 벡터를…
wikidocs.net
BERT에서 Sentence Embedding을 얻어내는 방법에도 여러 가지가 있으나, 세 가지 정도만 알아보자.
1. [CLS] Token을 이용

예를 들어, 위와 같이 "I love you"라는 문장이 입력으로 들어간다고 하자. 이 때, 이 문장에 대한 Embedding Vector를 얻는 방법으로, [CLS]토큰의 출력 벡터를 전체 문장의 벡터로 간주하는 것이다.
이는 [CLS] 토큰이 전체 입력 문장에 대한 총체적인 표현으로 간주되기 때문이다.
2. [CLS] Token뿐만 아니라, BERT의 모든 출력 벡터를 평균내기 - Mean Pooling

Word Embedding의 평균은, Sentence Embedding으로 간주할 수 있는데, 이건 BERT에서도 마찬가지이다.
BERT의 각 단어에 대한 출력 벡터를 평균((Mean)Pooling)내고, 이를 문장 벡터로 고려한다.
3. [CLS] Token뿐만 아니라, BERT의 모든 출력 벡터를 평균내기 - Max Pooling
2번 방식에서 평균 풀링을 최대값 풀링으로 바꾸는 방법이다.
평균 풀링은 문장 중 모든 단어의 의미를 균등하게 반영하는 것이라면
최대값 풀링은 문장 중 중요한 단어의 의미를 반영하는 것으로 생각하면 된다.
[SBERT란?]
SBERT는 BERT의 Sentence Embedding 성능을 집중적으로 개선시킨 모델이다(BERT를 Fine Tuning한 것이 SBERT이다.)
SBERT를 학습시키는 방법은 Sentence Pair Classification Task문제를 풀게 하는것과, Sentence Pair에 대한 Regression문제를 풀게 하는것 두 가지 정도로 나눌 수 있다.
1. Sentence Pair Classification Task문제를 풀게 하는 것
BERT한테 문장 쌍에 대한 분류 Task를 진행하는 것으로, NLI(Natural Language Inferencing)문제나 KorNLI(한국어 버전)을 풀게 하는 것이 대표적인 방법이다.

예를 들어, 위 NLI 데이터와 같이 Sentence Pair에 대해 서로가 수반(Entailment)관계인지, 모순(Contradiction)관계인지, 중립(Neutral)관계인지를 레이블링하게 하는 작업이다.
SBERT는 NLI 데이터를 학습하기 위해 아래와 같은 구조를 가진다.

문장 A, B를 각각 BERT에 입력으로 넣어주고, 평균 풀링이든 최대값 풀링이든 Pooling 단계까지 거쳐 Embedding을 만든다(u, v라고 하자)
그리고 u, v, |u-v| 이 세 개를 연결(Concatenation)한다. 이를 h라고 하자. (h = (u; v; |u-v|))
이 때, Sentence Embedding의 차원이 n이라면, h의 차원은 3n이 된다.
그리고 이 벡터 h를 출력층으로 보내, Multi Class Classification 문제를 풀도록 하자.
분류하고자 하는 클래스의 개수가 k라면, 3n*k의 크기를 가지는 행렬 Wy를 곱한 뒤 SoftMax 함수를 통과시켜 분류문제를 푼다.
식으로 표현한다면 다음과 같다.

이 값과 실제 값에 해당하는 레이블로부터 오차를 줄이는 방식으로 학습시킨다.
2. Sentence Pair에 대한 Regression문제를 풀게 하는것
SBERT를 학습하는 두 번째 방법은, Sentence Pair로 Regression문제를 푸는 것이다. 대표적으로 STS(Semantic Textual Similarity)문제를 풀게 하는 경우를 들 수 있다.
cf. KorSTS 데이터셋 : https://github.com/kakaobrain/KorNLUDatasets
GitHub - kakaobrain/kor-nlu-datasets: KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding
KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding - kakaobrain/kor-nlu-datasets
github.com

STS문제는, Sentence Pair에 대해 유사도를 측정하여, 0~5사이의 값으로 라벨링하는 문제이다.
SBERT는 STS 데이터를 학습하기 위해, 아래와 같은 구조를 갖는다.
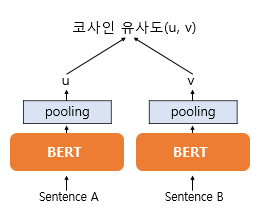
마찬가지로 문장 A, B 각각 BERT에 넣고, Pooling해주어 Embedding을 얻는다. 이걸 u, v라고 했을 때, 이 두 벡터의 Cosine Similarity를 구한다.
그리고 해당 유사도와 레이블 유사도와의 Mean Squared Error를 최소화하는 방식으로 학습을 한다.
코사인 유사도값의 범위는 -1 ~ 1 이므로, 0~5사이의 라벨링 값을 5로 나누어서 이 범위에 맞춰주어 학습할 수 있다.
정리하면, 문장 쌍 분류 태스크로만 Fine Tuning할 수도 있고, 문장 쌍 회귀 태스크로만 Fine Tuning할 수도 있고, 둘 다로 Fine Tuning할 수도 있다.
실습은 아래를 참조하자.
18. 실전! BERT 실습하기
이전 챕터에서 배웠던 BERT의 이론적 지식을 바탕으로 BERT로 풀 수 있는 다양한 문제들을 풀어봅시다. 기본적으로 transformers 패키지를 사용하여 트랜스포머 계열들의…
wikidocs.net
(Fine Tuning된 SBERT를 통해 한국어 챗봇을 만드는 실습이다)
'AI' 카테고리의 다른 글
| [GPU 메모리 절약] 메모리를 절약해서 학습시켜보자 (0) | 2024.12.14 |
|---|---|
| [시계열 데이터] Sequential Data의 Validation(Sequential Data의 Cross-Validation) (1) | 2024.12.12 |
| [Fine Tuning] PEFT(Parameter Efficient Fine Tuning), SFT(Supervised Fine Tuning) (2) | 2024.11.22 |
| [Prompting기법] LLM 모델의 추론 능력을 향상시키기 위해 고려할 사항들 (0) | 2024.11.20 |
| [Clustering] 실루엣 계수, KMeans(엘보우 기법), HDBSCAN (2) | 2024.11.18 |